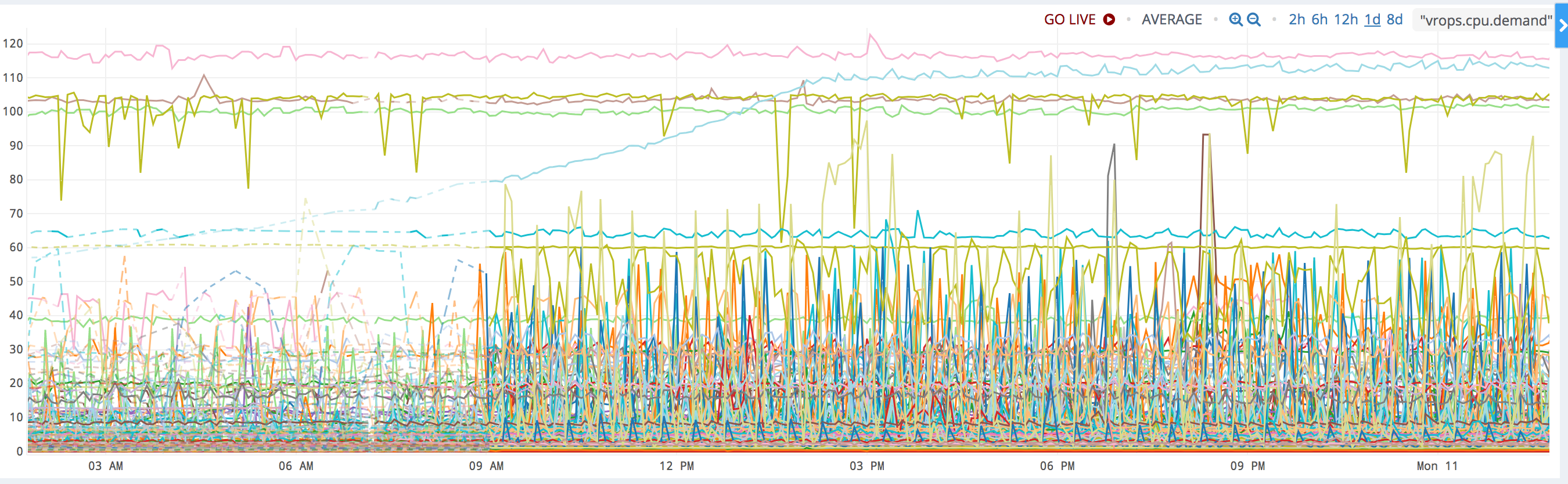
What is the Double Check pattern?
Synchronization in any programming language is considered to be expensive. The Double Check pattern is simply a way to try to eliminate locks by first testing for the existence of a resource without holding a lock and return the resource directly if it existed. If it didn’t exist, a lock is obtained and the check is done again, and if the resource still doesn’t exist, it’s created and returned. In Java it would look something like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class DoubleCheck { | |
| private SomeResource myResource; | |
| public SomeResource getResource() { | |
| if(myResource != null) { | |
| return myResource | |
| } | |
| synchronized(this) { | |
| if(myResource != null) { | |
| return myResource | |
| } | |
| myResource = new SomeResource(); | |
| return myResource | |
| } | |
| } | |
| } |
Why are two checks cheaper than one?
Locks can be expensive to manage. First of all, there’s the obvious situation where the lock is held by someone and your code has to wait. But even if no one is holding the lock, there could be some performance implications. Locks can be implemented in many different ways, but they all need some kind of so called atomic instruction. These are machine code instructions that guarantee thread safety at the hardware level. What this means is that they have to halt all other cores and hardware threads for a brief moment. There are also implications on hardware caches that could further slow down execution. Experiments have shown that an atomic instruction can be up to 30 times slower than its non-atomic counterpart.
So checking something without holding a lock seems like a much quicker way. Now the lock only needs to be held while a new resource is created. Most of the time, you’d just get the resource back without acquiring a lock! Great, isn’t it?
A Blatantly Broken Example
Recently I saw some code in a widely used package that prompted me to alert the maintainer. Someone was trying to save a few nanoseconds using a Double Check pattern in a place where it definitely didn’t belong. Here’s the essence of that code:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class BrokenDontUse { | |
| private Map<String, SomeResource> aHashMap = new HashMap<>(); | |
| public SomeResource getResource(String name) { | |
| SomeResource r = aHashMap.get(name); | |
| if(r != null) { | |
| return r; | |
| } | |
| synchronized(aHashMap) { | |
| SomeResource r = aHashMap.get(name); | |
| if(r != null) { | |
| return r; | |
| } | |
| r = new SomeResource(name); | |
| aHashMap.put(name, r) | |
| return r; | |
| } | |
| } | |
| } |
It should be pretty obvious why this is broken. A HashMap is inherently unsafe and the put operation may completely rearrange its internal structures. If the get should happen to execute at the same time, chances are very high that you’ll end up with strange results and very hard to find bugs.
In this case, you can still use the Double Check pattern. In fact, the code above only needs to change a single line to be safe. Instead if instantiating the Map as a HashMap, you could use a ConcurrentHashMap. This variant of a Map uses some clever tactics internally to make sure most accesses can take place without locks being acquired, while being guaranteed to be thread safe.
This ensures that we won’t run into strange bugs stemming from race conditions in the HashMap. But is this code really thread safe? Well, it depends…
Why Double Check May Be a Bad Idea
Even if you avoid the obvious HashMap problem, there’s still some potential issues here. Consider this code where we want to record when something was accessed for the first time. We could do that using a Double Check.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class QuestionableUseOfDoubleCheck { | |
| private long firstAccess = –1; | |
| public long accessSomething() { | |
| if (firstAccess != –1) { | |
| return this.firstAccess; | |
| } | |
| synchronized (this) { | |
| if (this.firstAccess != –1) { | |
| return this.firstAccess; | |
| } | |
| this.firstAccess = System.currentTimeMillis(); | |
| return this.firstAccess; | |
| } | |
| } | |
| } |
Looks pretty safe, doesn’t it? Well, on most modern processors this code IS safe. Storing and reading a 64-bit long should require a single instruction and a single access to memory across its 64-bit wide bus. But there’s no guarantee that’s the case. In fact, the Java spec explicitly states that 64-bit assignments are not guaranteed to be atomic. So what if someone tried to run your code on a 32-bit machine, like a Raspberry Pi? There’s a chance you’d see a timestamp where only half of the 64 bits had been updated!
Luckily, in Java there’s the volatile keyword. By declaring “firstAccess” volatile, you would guarantee that accesses to it are atomic. But guess what? Depending on your platform, you may now have introduced the need for an atomic instruction, which is what we tried to avoid in the first place!
Your JVM is Probably Smarter than You!
As we have seen, there’s really no safe way of avoiding synchronization or atomic accesses. And when it comes to synchronization, you should understand that in most cases, it’s pretty fast. Most languages implement synchronization something like this (pseudocode):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| int waiters = 0; | |
| void acquireLock() { | |
| if(atomicIncrement(waiters) == 0) { | |
| rerurn; | |
| } | |
| callSlowAndPainfulLockingLogic(); | |
| } |
Do you see what’s going on here? It’s pretty close to a Double Check pattern, isn’t it? It tries the quick and easy way first, then takes the more arduous route if needed. The “atomicIncrement” pseudo function deserves some explanation. Most modern CPUs have an instruction for atomically incrementing a value and returning what it was just before (or is some cases just after) it was incremented. The “waiters” variable holds the number of waiting threads. If I increment it atomically and the number before it was incremented is zero, I can be sure of two things: No one was holding it when I tried to take it and I now own it, since all other threads will see waiters > 0.
Yes, there’s still an atomic instruction here, but as we have shown above, you would need them anyway to implement a Double Check that’s truly safe.
Empirical Testing
So how much does really synchronization affect performance? The answer is, as usual, “it depends”.
On my MacBook Pro with an i7 processor, a loop incrementing a single integer 100,000,000 times took 112ms without a synch inside the loop. With a synch inside the look, it took 221ms. So a 100% performance degradation. That seems bad. Yes, but this isn’t a very realistic use case. How often do you write code like this? Rarely. Also, if we look at the cost for each synchronization, it’s around 2 nanoseconds! Yes, the impact could be higher on a very busy massively parallel machine, but it’s still fairly low for most operations.
Here’s the code:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public class Test { | |
| public static void main(String[] args) { | |
| int value = 0; | |
| long now = System.currentTimeMillis(); | |
| for(int i = 0; i < 1e8; i++) { | |
| value++; | |
| } | |
| System.out.println("Unsynched version took " + (System.currentTimeMillis() – now) + "ms"); | |
| Object syncher = new Object(); | |
| now = System.currentTimeMillis(); | |
| for(int i = 0; i < 1e8; i++) { | |
| synchronized(syncher) { | |
| value++; | |
| } | |
| } | |
| System.out.println("Synched version took " + (System.currentTimeMillis() – now) + "ms"); | |
| } | |
| } |
A more realistic example may be to access a HashMap 10,000,000 times. The unsynched version takes 40ms and the synched version takes 50ms. Still a difference, but there’s a very limited number of applications where such a difference would have any meaningful impact.
Again, here’s my example code in Java:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import java.util.HashMap; | |
| public class HashTest { | |
| public static void main(String[] args) { | |
| HashMap<String, String> map = new HashMap<>(); | |
| map.put("foo", "bar"); | |
| long now = System.currentTimeMillis(); | |
| for(int i = 0; i < 1e7; i++) { | |
| map.get("foo"); | |
| } | |
| Object syncher = new Object(); | |
| System.out.println("Unsynched version took " + (System.currentTimeMillis() – now) + "ms"); | |
| now = System.currentTimeMillis(); | |
| for(int i = 0; i < 1e7; i++) { | |
| synchronized(syncher) { | |
| map.get("foo"); | |
| } | |
| } | |
| System.out.println("Synched version took " + (System.currentTimeMillis() – now) + "ms"); | |
| } | |
| } |
When Does Double Check Make Sense?
So far, this article reads like I’m bashing the Double Check pattern. In fact, that’s not at all what I’m trying to do. What I’m worried about are all the improper uses of Double Check that I’ve seen and how they could introduce some very subtle and hard-to-find bugs. It also makes the code more complex and a but harder to maintain. But it does have its virtues.
So by all means, use Double Check, but use it with caution and only when it makes sense!
Here are some basic rules.
Use Double Check when the lock contention in the fast path is likely
If your code is called millions of times per second, there’s a high likelihood that threads will be stuck waiting on a lock for no reason. If performance is an issue, you may consider implementing a “fast path” that doesn’t require locking.
Your fast path MUST use atomic accesses only!
In Java, with the exception of object reference assignment and assignment of 32-bit datatypes, nothing is atomic. So you need to take care that your fast path takes the appropriate precautions to make sure all accesses are atomic. The volatile keyword or the java.util.concurrent.atomic package are very useful.
Also keep in mind that even if you make atomic accesses, you’re typically only allowed one such access in your fast path. If you check more than one value, your code is not atomic anymore and may very well end up in a race condition with the slow path.
Consider using a read/write lock!
Sometimes it’s not possible to make the fast path fully atomic. Does that mean that all hope is lost for Double Check? Not necessarily! You can use something like a java.util.concurrent.locks.ReadWriteLock. These are what’s known as asymmetric locks which allows multiple readers, but only one writer. Once the writer acquires a lock, it also blocks all readers. I’m planning to write an article about this in the near future, but in basic terms, you would essentially wrap a read lock around your fast a path and a write lock around the slow path.
Document, document and document! Did I mention “document”?
When you’re implementing a Double Check pattern, add code comments clearly stating what you’re doing. Some maintainer may poke around in the code without understanding the requirements for the fast path to be atomic and someone may have to spend days or weeks chasing strange bugs!
The catch-all: Use only when needed!
I recently reviewed some code where a Double Check pattern was used in a function that was called maybe ten times during application startup. To make matters worse, the code had a subtle bug in it. So the developer shaved maybe a couple of microseconds off the application startup time at the expense of code complexity that caused a bug. So don’t bother using this pattern unless you expect your code to be called very frequently and where lock contention could have a meaningful impact on performance!
Conclusion
The Double Check pattern can be a life saver when you are under heavy performance requirements with code that’s called millions or billions of times. But there are many pitfalls and I’ve seen a fair amount of bugs caused by programmers that don’t fully understand the semantics of the pattern. So use it with care and only when needed!
Follow me on Twitter @prydin!













![{\displaystyle {\begin{aligned}F_{R}(f)&=\operatorname {FFT} [X(t)]\\S(f)&=F_{R}(f)F_{R}^{*}(f)\\R(\tau )&=\operatorname {IFFT} [S(f)]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/41ba8c3c366062d1c22b4ad97968f52961a40e82)