Yes, I’m cheap!
I guess I’m a bit cheap when it comes to buying equipment for my lab. To be honest, I’m more interested in funneling money to my hobbies and my wife’s hobbies than spending money on an elaborate lab. However, since I felt the need of a true sandbox where I could experiment freely, I arrived at a point when a home lab was more or less necessary.
So I set out to create the most inexpensive lab that would still get the job done. It became almost an obsession. Was it possible to build a viable lab for less than $500? The result was pretty astonishing, so I decided I wanted to share it.
Requirements
I needed a demo lab where I could run most or all of the vCloud Suite products as well as NSX. It didn’t have to be extremely beefy, but fast enough to run demos without making the products look slow. Here’s a condensed list of requirements:
- Run the basic components of the vCloud Suite: vRealize Automation, vRealize Orchestrator, vRealize Operations, LogInsight.
- Run some simulated workloads, including databases and appservers.
- Run a full installation of NSX
- Provide a VPN and some simplistic virtual desktops.
- Have at least 1GB Ethernet connections between the hardware components.
Deciding on hardware
I did a lot of research on various hardware alternatives. Let’s face it: What it comes down to is RAM. In a lab, the CPUs are waiting for work most of the time, but the vCloud Suite software components eat up a fair amount of memory. I calculated that I needed about 100GB or RAM for it to run smoothly.
At first, I was looking at older HP Proliant servers. I could easily get a big DL580 with 128GB RAM for about $200-300. But those babies are HUGE, make tons of noise and suck a lot of power. Living in a normal house without a huge air conditioned server room and without a $100/month allowance for powering a single machine, this wasn’t really an alternative.
My next idea was to buy components for bare-bones systems with a lot of memory. I gave up that idea once the value of my shopping cart topped $3000.
I was about to give up with I found some old Dell Precision 490 desktops on eBay. These used to be super-high-end machines back in 2006-2007. Now, of course they are hopelessly obsolete and are being dumped on eBay for close to nothing. However, they have two interesting properties: They run dual quadcore Xeon CPUs (albeit ancient) and your can stuff them with 32GB of RAM. And, best of all, they can be yours for about $160 from PC refurbishing firms on eBay. On top of that, memory upgrades to 32GB can be found for around $40.
Waking up the old dinosaurs
So thinking “what do I have to lose?” I ordered two Dell Precision 490 along with a 32GB memory upgrade for each one. That all cost me around $400.
I fired everything up, installed ESXi 6 and started spinning up VMs with software. To my surprise and delight, my old dinosaurs of ESXi servers handled it beautifully.

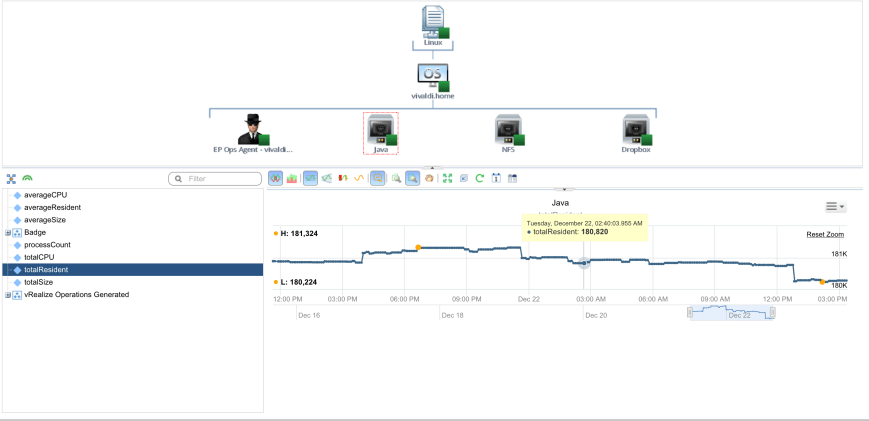
Here’s what vRealize Operations had to say about it.

As you can see, my environment is barely breaking a sweat. And that’s running vRealize Operations, vRealize Operations Insigt, vRealize Automation 6.2, vRealize Operations 7.0 Beta, NSX controllers and edges along with some demo workloads including a SQL Server instance and an Oracle instance. Page load times are surprisingly fast too!
A Jumbo Sized Problem!
After a while I noticed that some NSX workloads didn’t want to talk to each other. After some troubleshooting I realized that there was an MTU issue between the two ESXi servers. Although the Distributed vSwitch was configured for an MTU of 6000 bytes without complaining, the physical NICs were still pinned at 1500 bytes MTU. Turns out, the on-board NIC in the Precision 490 doesn’t support jumbo frames.
The only way to fix this seems to be to use another NIC, so I went back and got myself two Intel PRO/1000 GT Desktop Adapters. They normally run about $30-35, but I was lucky enough to find some Amazon vendor who had them on sale for $20 a piece. If you didn’t already know it, the Intel PRO/1000 GT has one of the most widely supported chipsets, so it is guaranteed to run well with virtually any system. And it’s cheap. And supports jumbo frames.
How much did I spend?
I already owned some of the necessary components (more about that later), so I cheated a little when meeting my $500 goal. Here’s a breakdown of what I spent:
$320 – 2x Dell Precision 490 2×2.66GHz Quad Core X5355 16GB 1TB
$80 – 2x 32GB Memory Upgrade
$40 – 2x Intel PRO/1000 GT
This adds up to $440. Add some shipping to it, and we just about reach $500.
Vendors
I got the servers from the SaveMyServer eBay store. Here is their lineup of Dell Precision 490.
The memory is from MemoryMasters.
The network adapters are from Amazon. There’s a dozen of vendors that carry it. I just picked the cheapest one.
What else do you need?
In my basement I already had the following components:
1 Dell PowerEdge T110 with 16GB memory
1 old PC running Linux with 2x 2GB disks in it.
1 16 port Netgear 1GB/s Ethernet switch.
Assuming you already own a switch and some network cables, you’ll need at least some kind of NAS. I just took an old PC, loaded CentOS on it and set up and NFS share. That worked fine for me. Not the fastest when you’re seeing IO peaks, but for normal operations it runs just fine. You can also get e.g. a Synology NAS. With some basic disks, that’s going to set you back about $300.
I already had an old ESXi server (the PowerEdge T110) and I decided to run my AD, vCenter and NSX Manager on it. I could probably have squeezed it into the two Precision 490, but it’s a good idea to run the underpinnings, such as vCenter and AD on a separate machine. If I didn’t already had that machine, I would probably have ordered three of the Precision 490 and used one for vCenter and AD.
Room for improvement
Backup
The most dire need right now is backup. Although my NAS runs a RAID1 and gives me some protection, I’m still at risk of losing a few weeks of work in setting up vCloud Suite the way I wanted it. I’ll probably buy a Synology NAS at some point and set it up to replicate to or from my old NAS.
Network
Currently, everything runs on the same physical network. This is obviously not a good design, since you want to at least separate application traffic, management traffic, storage traffic and vMotion into separate physical networks. I might not get to four separate networks, but I would like to separate storage traffic from the rest. Given that I have free NIC on the motherboard, it’s just a matter of cabling and a small switch to get to that point.
Backup power
I’ve already had a power outage in my house since I built this lab. And booting up all my VMs on fairly slow hardware wasn’t the greatest thing in the world. I’ll probably get a small UPS that can last me through a few minutes of power outage, at least until I can get my generator running.
A final word
If you have a few hundred dollars and a few days to spend, I highly recommend building a simple lab. Not only is it great to have an environment that works just the way you want it, you’ll also learn a lot from setting it up from scratch. In my line of work, the infrastructure is already there when I get on the scene, so it was extremely valuable to immerse myself into everything that’s needed to get to that point.
I’d also like to thank my friend Sid over at DailyHypervisor for his excellent tutorials on how to set up NSX. I would probably still have been scratching my head if it wasn’t for his excellent blog. Check it out here on DailyHypervisor.